
随着嵌入式系统变得越来越智能,对嵌入式处理器的要求也越来越高。为了更好应对汽车、医疗和工业机器人等领域对嵌入式处理器的要求,Arm推出了采用Armv8-R架构的Cortex-R52。Cortex-R52相对之前的处理器引入了很多新的特性,其中一个就是NEON。本文主要介绍如何在IAR Embedded Workbench for Arm中使用Arm Cortex-R52 NEON。
注意:由于Cortex-R52和Cortex-R52+具有相同的指令集并且软件兼容, 除非特别说明,本文中的Cortex-R52同时包括Cortex-R52和Cortex-R52+。
Arm Cortex-R52 NEON介绍
Arm NEON概述
大多数Arm指令是单指令单数据(SISD,Single Instruction Single Data):即每条指令对单个数据执行指定的操作,因此,处理多个数据需要多条指令,相对较慢。为了提高性能和效率,Arm推出了对应的高级单指令多数据 (SIMD, Single Instruction Multiple Data)架构扩展NEON。Arm NEON 是针对Armv8架构Cortex-A和Cortex-R处理器的高级单指令多数据架构扩展。

单指令多数据指令可同时对多个数据执行相同的操作,如果数据处理很简单并且重复多次,单指令多数据指令可以带来显著的性能提升。
如下图所示,单指令多数据指令 (ADD V10.4S, V8.4S, V9.4S)可以同时对4个数据进行加法运算:

Arm NEON寄存器 (Registers), 向量 (Vectors), 通道 (Lanes)和元素 (Elements)
Arm处理器有通用寄存器(R0-R15),AArch32的通用寄存器宽度是32位,AAarch64的通用寄存器宽度是64位。Arm NEON有对应的NEON寄存器(NEON寄存器数目跟对应处理器相关),NEON寄存器宽度是128位,同时NEON寄存器可以8位、16位、32位、64位或128位寄存器访问。NEON寄存器包含相同数据类型元素 (Elements)的向量 (Vectors),输入和输出NEON寄存器中相同的元素(Elements)位置称为通道(Lanes)。
通常,每条NEON指令会并行执行n个操作,其中n是输入向量被划分为的通道数。每个操作都包含在通道中,从一个通道到另一个通道不能有进位或溢出。NEON向量中的通道数量取决于向量的大小和向量中的元素大小。
128位NEON向量可以包含以下元素大小:
- 16个8位元素(操作数后缀.16B,其中B表示字节Byte)
- 8个16位元素(操作数后缀.8H,其中H表示半字Half word)
- 4个32位元素(操作数后缀.4S,其中S表示单字Single word)
- 2个64位元素(操作数后缀.2D,其中D表示双字Double word)
64位NEON向量可以包含以下元素大小(128位寄存器的高64位清零):
- 8个8位元素(操作数后缀.8B,其中B表示字节Byte)
- 4个16位元素(操作数后缀.4H,其中H表示半字Half word)
- 2个32位元素(操作数后缀.2S,其中S表示单字Single word)
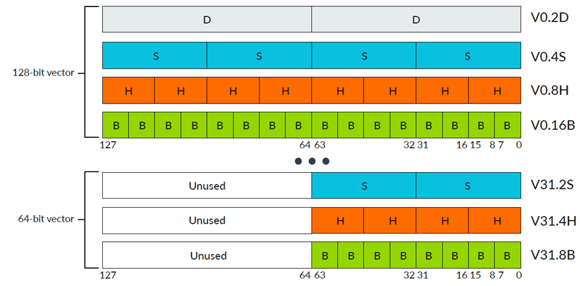
向量中的元素从最低有效位开始排序,元素0使用最低有效位。
下面是8个通道16位元素(8*16 =128)相加的示例:

Arm Cortex-R52 NEON概述
Arm Cortex-R52属于Armv8-R架构,Armv8-R架构本身支持NEON,Cortex-R52具有对应的NEON配置选项:只支持单精度浮点运算或者支持单精度、双精度浮点运算和NEON。


Cortex-R52 NEON包含16个128位的寄存器,这些寄存器可以当作32位的单精度寄存器S0-S31,64位的双精度寄存器D0-D31或者128位的四字寄存器Q0-Q15:
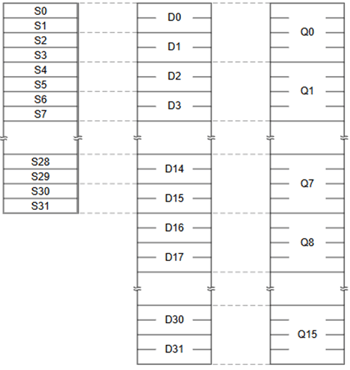
Arm NEON使用介绍
作为程序员,您可以有多种方法使用Arm NEON:
支持Arm NEON的库
使用支持Arm NEON的库(比如Arm Compute Library, Ne10等库)可以很快捷方便地使用Arm NEON。
编译器自动向量化(Auto-vectorization)
编译器自动向量化可以自动优化代码,充分利用Arm NEON。编译器自动向量化一般包含两部分:
- 循环向量化(Loop vectorization):展开循环以减少迭代次数,同时在每次迭代中执行更多操作;
- 超字并行向量化(SLP,Superword-Level Parallelism vectorization):将多个标量运算绑定到一起,使其成为向量运算,以充分利用高级单指令多数据指令。
NEON内在(intrinsics)函数
NEON内在函数是编译器用适当的 NEON指令替换的函数调用。NEON内在函数提供的控制几乎与编写汇编语言一样多,但将寄存器的分配留给编译器,以便开发人员可以更专注于算法。NEON内在函数在arm_neon.h中定义。
NEON汇编
为了获得非常高的性能,对于经验丰富的程序员来说,编写 NEON汇编也是一种选择。
在IAR Embedded Workbench for Arm中使用Arm Cortex-R52 NEON
前面介绍了Arm NEON的基本概念和对应的使用方法,下面介绍如何在IAR Embedded Workbench for Arm中使用Arm Cortex-R52 NEON,主要包括使用编译器自动向量化和NEON内在函数。
编译器自动向量化
编译器自动向量化需要指定对应的编译器选项才能让编译器进行对应的自动向量化优化:
- 对应的处理器支持NEON
- 对应的编译选项使能编译器自动向量化
首先要确保对应的处理器支持NEON:
对应的Core要选择为Cortex-R52/Cortex R52+: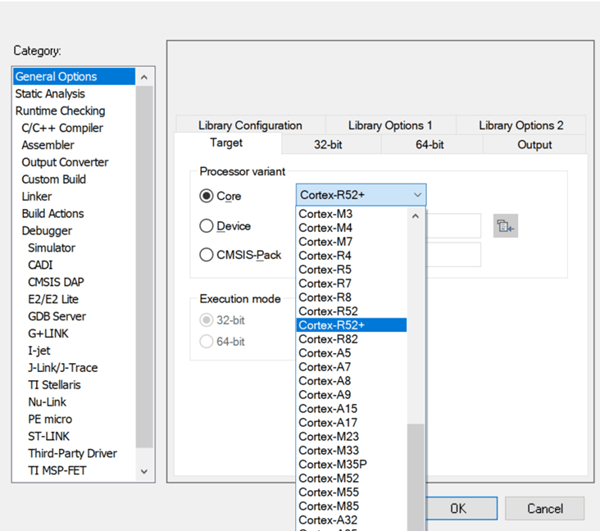
同时对应FPU要选择为VFPv5 double precision, D registers要选择为32,并且要勾选Advanced SIMD (NEON/HELIUM)选项:
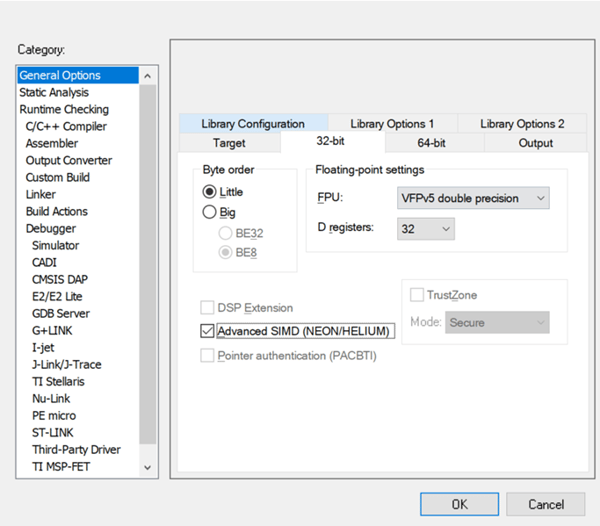
对应CPU和FPU的编译器选项分别为:--cpu=Cortex-R52/Cortex-R52+和--fpu=VFPv5。
然后对应的编译器优化选项要使能编译器自动向量化:
编译器优化等级需要选择为High Speed,并且勾选Vectorization选项才会使能编译器自动向量化:
对应编译器优化等级和自动向量化的编译器选项分别为:-Ohs和--vectorize。
另外可以通过#pragma vectorize命令对后面的循环单独使能/不使能编译器自动向量化(只有在编译器优化等级为High的时候#pragma vectorize命令才会生效):

下面通过一个简单的示例进行介绍:
{
int i;
for (i=0; i<len_vec; i++)
{
vec_C[i] = vec_A[i] * vec_B[i];
}
}
首先不使能编译器自动向量化进行编译,然后查看对应的反汇编代码(可以使用ielfdumparm xxx.o xxx.txt --code --source命令将对应的.o文件输出为对应的.txt文件),对应的乘法操作采用的是普通的乘法指令MULS R5, R4, R5:

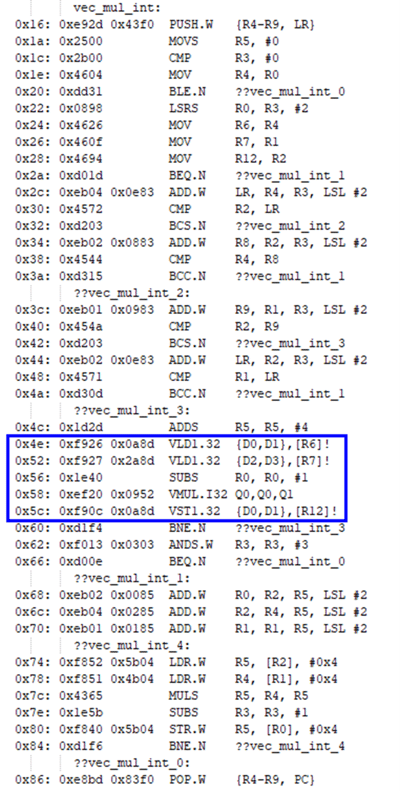
然后使能编译器自动向量化进行编译,查看对应的反汇编代码使用了NEON相关的高级单指令多数据指令,其中乘法操作使用了VMUL.I32 Q0,Q0,Q1指令,同时对4个32位整型数据(.I32)进行乘法操作(VMUL):
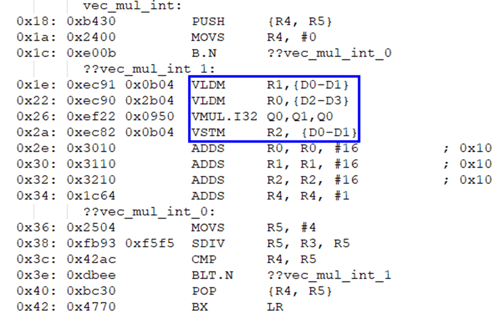
NEON内在函数
使用NEON内在函数需要包含对应的头文件 arm_neon.h:
void vec_mul_int(int* vec_A, int* vec_B, int* vec_C, int len_vec)
{
int i;
for (i=0; i<(len_vec / 4); i++)
*((int32x4_t*)vec_C) = vmulq_s32(*((int32x4_t*)vec_A), *((int32x4_t*)vec_B));
vec_A = vec_A + 4;
vec_B = vec_B + 4;
vec_C = vec_C + 4;
}
}
总结
本文首先介绍了Arm NEON的基本概念,然后介绍了使用Arm NEON的通用方法,最后详细介绍了如何在IAR Embedded Workbench for Arm中使用Arm Cortex-R52 NEON,包括使用编译器自动向量化和NEON内在函数,用户可以根据项目具体情况选择合适的策略。
参考资料:
- https://developer.arm.com/Architectures/Neon
- Learn the architecture - Introducing Neon
- Learn the architecture - Compiling for Neon with auto-vectorization
- Learn the architecture - Optimizing C code with Neon intrinsics
- Arm C Language Extensions
- Arm Neon Intrinsics Reference
- Arm Cortex-R52/Cortex-R52+ Processor Technical Reference Manual
- EWARM Development Guide
