
정확한 타이밍, 예측 가능한 성능을 제공하는 GLIWA T1 및 IAR
GLIWA T1은 자동차 산업에서 가장 많이 사용되는 타이밍 툴로, 수백 개의 양산 프로젝트에서 수년 동안 사용되고 있습니다.
세계 최초로 ISO 26262 ASIL-D 인증을 받은 T1-TARGET-SW는 안전한 계측 기반 타이밍 분석 및 타이밍 감독을 가능하게 합니다. 차량에서. 대량 생산에서.
완벽한 조합: GLIWA T1과 IAR
다른 컴파일러 툴 제품군 중에서도 GLIWA T1은 사전 인증된 에디션을 포함하여 Arm Cortex-M 프로세서를 위한 IAR 임베디드 개발 툴을 지원합니다. 이는 IAR 툴체인이 제공하는 최적화가 T1의 요구 사항과 완벽하게 일치하기 때문에 매우 만족스러운 조합으로 밝혀졌습니다.
타이밍 측정 솔루션 T1을 사용하면 소프트웨어의 실시간 특성에 대한 직관적인 통찰력을 얻을 수 있습니다. 이 솔루션은 휴대용 소프트웨어 전용 솔루션으로, 측정 대상 소프트웨어의 계측을 포함하며, 실시간 운영 체제(RTOS)가 작업을 전환할 때 타임스탬프와 함께 이벤트를 기록하는 T1_TraceEvent()를 호출합니다. 그런 다음 누적된 여러 이벤트의 추적을 PC에 업로드하여 추적을 시각화할 수 있습니다. 갑자기 시간이 너무 오래 걸리거나 너무 짧게 걸리는 작업, 또는 일부 인스턴스가 완전히 누락되는 등 예기치 않은 동작을 확인할 수 있습니다(몇 가지 예만 들어보겠습니다).
T1 내부 직관적인 실시간 인사이트
다음 스크린샷은 T1의 T1.scope 시각화를 보여줍니다. 이를 통해 사용자는 시스템 내의 시간적 동작을 명확하게 이해할 수 있습니다. 다른 기능 외에도 T1은 시스템 분석을 효율적으로 지원하기 위해 모든 관련 타이밍 메트릭(CET, GET, DT 등)에 대한 프로파일링을 제공합니다.
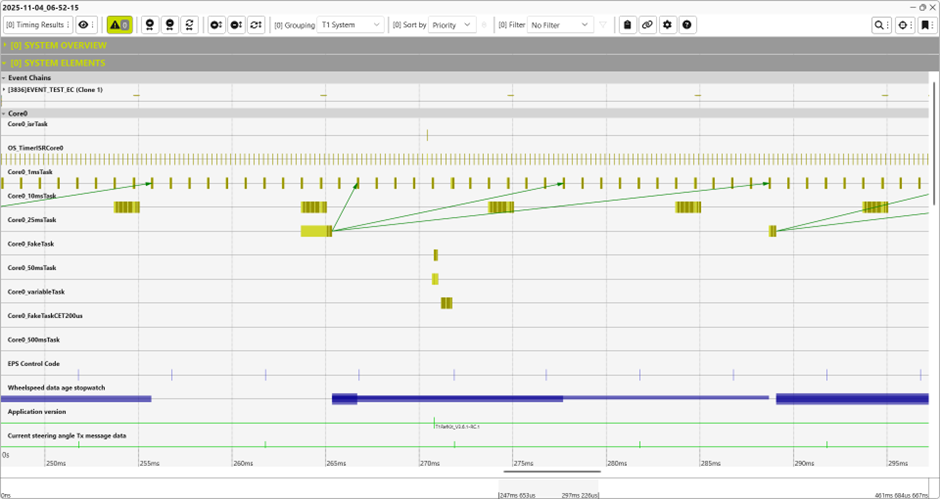
소프트웨어 기반 추적은 T1에만 있는 것이 아닙니다. T1은 가장 오래되고 가장 원시적인 추적 및 디버깅 방법 중 하나인 인쇄 디버깅의 한 종류로 간주될 수 있습니다. T1이 특별한 이유는 리소스가 제한된 임베디드 시스템 영역에서 효과적이라는 점입니다. 소프트웨어 기반 추적의 근본적인 문제는 계측이 측정하려는 시스템을 변경한다는 것입니다. 오버헤드가 너무 높으면 시스템이 충분히 잘 실행되지 않아 유용한 타이밍 데이터를 얻을 수 없습니다. 이런 의미에서 T1에서 최소한의 것을 얻는 것이 바람직합니다. 오버헤드가 매우 낮더라도 오버헤드가 매우 안정적이라면 오버헤드의 영향을 파악할 수 있지만, 오버헤드가 매우 가변적이라면 애플리케이션이 실제로 사용한 시간과 T1 계측이 사용한 시간을 추측할 수 있을 뿐입니다.
IAR을 통해 안정적이고 예측 가능한 타이밍을 확보하는 방법
사전 처리된(따라서 "마법 같은" 숫자가 많은) C 소스를 통해 T1과 IAR C/C++ 컴파일러를 포함한 IAR 툴체인 간의 행복한 결합을 보여주는 작은 예를 살펴봅시다. 이 루틴은 추적된 이벤트의 일부 사전 처리를 수행하여 결합된 'eventInfo' 값을 구성 요소 이벤트와 정보 필드로 분리하고 주어진 이벤트에 적합한 이벤트 핸들러를 선택합니다. 큰 'if' 조건은 이벤트가 주어진 값 집합 중 하나인지 확인하는 테스트입니다. 순진한 접근 방식은 if-else 조건의 시퀀스 또는 스위치 문을 사용하는 것입니다. 컴파일러가 보다 효율적인 솔루션을 찾도록 돕기 위해 비트 마스크를 사용하는데, 이는 앞으로 살펴보겠지만 IAR과 매우 잘 작동합니다.
T1_tickUint_t T1_TraceEventNoSusp__( T1_scopeFgConsts_t *pScopeConsts, T1_eventInfo_t eventInfo ){ T1_uint8Least_t 핸들러Idx; T1_uint16Least_t eventId = ( eventInfo >> 10 ) & 0x3Fu; eventId = ( 15u < eventId ) ? 15u : eventId; handlerIdx = 0u; if( 0uL!= ( ( ( 1uL << 12u ) | ( 1uL << 1u ) | ( 1uL << 3u ) | ( 1uL << 2u ) | ( 1uL << 14u ) | ( 1uL << 13u ) | ( 1uL << 4u ) | ( 1uL << 5u ) | ( 1uL << 6u ) | ( 1uL << 8u ) | ( 1uL << 7u ) ) >> eventId ) & 1uL ) ) { 핸들러Idx = eventId; eventInfo &= 0xFFFFFFFFuL >> ( 32 - 10 ); } 반환 pScopeConsts->pDispatcher( pScopeConsts, eventInfo, handlerIdx << 1 );}
이제 컴파일러의 분해된 출력을 살펴봅시다.
T1_TraceEventNoSusp__: 0x3f20: 0x0a8b LSRS R3, R1, #10 0x3f22: 0x2b0f CMP R3, #15 ; 0xf 0x3f24: 0xbf28 IT CS 0x3f26: 0x230f MOVCS R3, #15 ; 0xf 0x3f28: 0xf247 0x12fe MOVW R2, #29182 ; 0x71fe 0x3f2c: 0x40da LSRS R2, R2, R3 0x3f2e: 0xf012 0x0201 ANDS.W R2, R2, #1 0x3f32: 0xbf1c ITT NE 0x3f34: 0x005a LSLNE R2, R3, #1 0x3f36: 0xf3c1 0x0109 UBFXNE R1, R1, #0, #10 0x3f3a: 0x6a43 LDR R3, [R0, #0x24] 0x3f3c: 0x4718 BX R3 0x3f3e: 0xbf00 NOP
가장 먼저 주목해야 할 것은 스택 프레임이 없다는 것입니다. pDispatcher를 통한 함수 호출은 BX 명령어로 테일 콜에 최적화되어 있습니다. 이는 컴파일러가 함수 휘발성 레지스터만 사용한다는 것과 결합되어 스택 프레임이 필요하지 않음을 의미합니다. 이렇게 작은 함수의 경우 스택 프레임을 할당하고 해제하는 데 드는 오버헤드가 상당했을 것입니다.
다음으로 주목해야 할 점은 조건 분기가 없다는 것입니다. 두 개의 조건('?:' 1개와 'if' 1개)은 IT 블록에서 Thumb2 조건부 명령어를 사용하여 컴파일되었습니다. 이 분기 없는 코드는 버스트 페치가 있는 최신 파이프라인 Arm 프로세서에서 특히 잘 실행됩니다. 분기 예측이 잘못될 가능성을 제거할 뿐만 아니라 제한된 분기 예측 리소스를 그대로 유지하므로 호출 코드 컨텍스트의 성능이 향상될 수 있습니다. 그리고 무엇보다도 조건부 브랜치보다 타이밍이 훨씬 더 안정적이라는 점이 가장 중요합니다. 집합 멤버십에 대한 비트 마스크 트릭은 확실히 효과가 있었습니다.
컴파일러가 제대로 처리하는데 왜 어셈블리를 작성할까요?
또 다른 주목할 만한 최적화는 코드를 작게 만들기 위해 대부분 16비트 Thumb 명령어를 사용하는 것입니다. 명령어가 작다고 해서 본질적으로 더 빠른 것은 아니지만, 코드가 작아지면 명령어 캐시가 더 많이 사용됩니다. 또한 캐시 라인 수를 줄이기 위해 코드 정렬을 위한 IAR 툴체인 지원은 코드 끝에 NOP를 설명하는 T1에서 활용됩니다. 이는 후속 함수가 8바이트 정렬되도록 하기 위한 패딩입니다. 프로세서 캐시를 몰라도 8바이트 코드 정렬은 코드 크기/패딩과 성능 간에 좋은 균형을 이룹니다.
이 글을 마무리하면서 이 코드의 성능에 그렇게 신경을 쓴다면 왜 어셈블리로 작성하지 않는지 궁금하실 것입니다. 몇 가지 요인이 있는데, 주로 전반적인 비용/편익을 고려한 것입니다. IAR C/C++ 컴파일러가 이식 가능한 C로 고품질의 객체 코드를 생성할 때 이식 불가능한 어셈블리 코드를 작성하고 유지보수하는 데 드는 비용을 정당화할 수 없기 때문입니다.
다음 단계는 무엇인가요?
GLIWA T1과 IAR이 다음 자동차 프로젝트를 어떻게 향상시킬 수 있는지 알아보세요 . GLIWA의 타이밍 툴과 IAR이 자동차 임베디드 개발을 지원하는 방법을 살펴보고 , IAR의 기능 안전 솔루션의 대화형 데모를 체험해 보세요.
이 블로그 게시물의 제목은 Jakob Engblom의 대표 논문인 'C 컴파일러를 최대한 활용하기'에 대한 헌정입니다.
