
GLIWA T1とIARが実現する、高精度なタイミングと予測可能なパフォーマンス
GLIWA T1は、自動車業界で最も頻繁に採用されているタイミング解析ツールであり、長年にわたり数百もの量産プロジェクトで使用されてきました。
世界初の試みとして、ISO 26262 ASIL-D認証を取得した「T1-TARGET-SW」は、コード埋め込み(インストルメンテーション)ベースの安全なタイミング解析と監視を可能にします。それも、実車内かつ量産環境においてです。
完璧な組み合わせ:GLIWA T1とIAR
数あるコンパイラ・ツール・スイートの中でも、GLIWA T1はArm Cortex-Mプロセッサ用のIAR組み込み開発ツール(機能安全認証済みエディションを含む)をサポートしています。IARツールチェーンが提供する最適化はT1の要件と完璧に合致するため、これは非常に相性の良い組み合わせといえます。
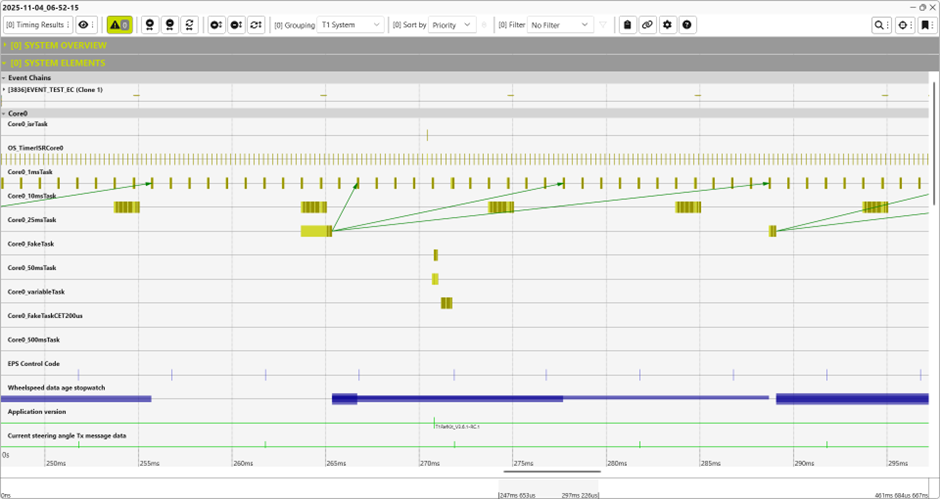
タイミング計測ソリューションであるT1を使用すると、ソフトウェアのリアルタイム特性を直感的に把握できます。これはポータブルなソフトウェア・オンリーのソリューションであり、計測対象のソフトウェアにコードを埋め込むことで機能します。例えば、リアルタイムOS(RTOS)がタスクを切り替える際に T1_TraceEvent() が呼び出され、タイムスタンプとともにイベントを記録します。蓄積された膨大なイベントのトレースをPCにアップロードして視覚化することで、処理時間が長すぎる、あるいは短すぎるタスクや、完全に実行漏れが発生しているタスクなど、予期せぬ挙動を一目で特定できるようになります。
T1の内部:リアルタイムの直感的な洞察
T1.scopeによる可視化により、ユーザーはシステム内の時間的挙動を明確に理解できます。また、T1は他の機能に加えて、あらゆる主要なタイミング指標(CET, GET, DTなど)のプロファイリングを提供し、効率的なシステム分析をサポートします。
ソフトウェアベースのトレース自体は、T1固有のものではありません。T1は、最も古く原始的なデバッグ手法である「printfデバッグ」の一種と見なすこともできるでしょう。T1を特別なものにしているのは、リソース制約の厳しい組み込みシステム領域におけるその有効性です。ソフトウェアベースのトレースにおける根本的な問題は、計測用のコードを埋め込むことで、計測対象のシステム自体に変化を与えてしまう点です。もしオーバーヘッドが大きすぎれば、有用なタイミングデータが得られるほどシステムが正常に動作しなくなります。この意味において、T1による影響を「最小限に(get the least)」抑えることが望ましいのです。たとえわずかなオーバーヘッドであっても、それが安定していれば影響を特定できますが、変動が激しいと、どこまでがアプリケーションの処理で、どこからがT1の処理なのかを推測することしかできなくなってしまいます。
IARがいかにして安定し予測可能なタイミングを実現するか
T1とIAR C/C++コンパイラを含むツールチェーンとの「最高の組み合わせ」を示す、小規模なコード例(プリプロセス済みのため「マジックナンバー」が多く含まれます)を見てみましょう。このルーチンは、トレースされたイベントの事前処理を行い、複合的な eventInfo 値をイベントフィールドと情報フィールドに分割し、適切なイベントハンドラを選択します。巨大な if 条件は、イベントが特定のセットに含まれるかどうかをテストしています。素直な実装なら if-else の連続や switch 文を使うところですが、ここではコンパイラがより効率的な解決策を見つけられるようビットマスクを使用しています。これがIARにおいていかにうまく機能するか、次で確認しましょう。
T1_tickUint_t T1_TraceEventNoSusp__( T1_scopeFgConsts_t *pScopeConsts, T1_eventInfo_t eventInfo ){ T1_uint8Least_t handlerIdx; T1_uint16Least_t eventId = ( eventInfo >> 10 ) & 0x3Fu; eventId = ( 15u < eventId ) ? 15u : eventId; handlerIdx = 0u; if( 0uL != ( ( ( ( 1uL << 12u ) | ( 1uL << 1u ) | ( 1uL << 3u ) | ( 1uL << 2u ) | ( 1uL << 14u ) | ( 1uL << 13u ) | ( 1uL << 4u ) | ( 1uL << 5u ) | ( 1uL << 6u ) | ( 1uL << 8u ) | ( 1uL << 7u ) ) >> eventId ) & 1uL ) ) { handlerIdx = eventId; eventInfo &= 0xFFFFFFFFuL >> ( 32 - 10 ); } return pScopeConsts->pDispatcher( pScopeConsts, eventInfo, handlerIdx << 1 );}
それでは、コンパイラが出力した逆アセンブル結果を見てみましょう。
T1_TraceEventNoSusp__: 0x3f20: 0x0a8b LSRS R3, R1, #10 0x3f22: 0x2b0f CMP R3, #15 ; 0xf 0x3f24: 0xbf28 IT CS 0x3f26: 0x230f MOVCS R3, #15 ; 0xf 0x3f28: 0xf247 0x12fe MOVW R2, #29182 ; 0x71fe 0x3f2c: 0x40da LSRS R2, R2, R3 0x3f2e: 0xf012 0x0201 ANDS.W R2, R2, #1 0x3f32: 0xbf1c ITT NE 0x3f34: 0x005a LSLNE R2, R3, #1 0x3f36: 0xf3c1 0x0109 UBFXNE R1, R1, #0, #10 0x3f3a: 0x6a43 LDR R3, [R0, #0x24] 0x3f3c: 0x4718 BX R3 0x3f3e: 0xbf00 NOP
まず注目すべきは、スタックフレームが存在しないことです。pDispatcher を介した関数呼び出しは、BX 命令による末尾呼び出し最適化(tail-call optimization)が行われています。これに加えて、コンパイラが揮発性レジスタのみを使用しているため、スタックフレームの確保が必要なくなっています。このような小規模な関数の場合、スタックフレームの生成と破棄に伴うオーバーヘッドは無視できないものになります。
次に注目すべきは、条件分岐が存在しない点です。2つの条件判定(3項演算子と if 文)は、IT ブロックを用いたThumb2条件実行命令にコンパイルされています。このブランチレス(分岐なし)コードは、バーストフェッチを備えた現代的なパイプライン型のArmプロセッサで極めて高速に動作します。分岐予測ミスの可能性を排除するだけでなく、限られた分岐予測リソースを消費せずに済むため、呼び出し元のコード実行にもプラスの影響を与えます。そして何より、条件分岐を使うよりもタイミングが遥かに安定します。ビットマスクを使って集合所属を確認するテクニックは、確実に見返りをもたらしました。
コンパイラが正解を出すのに、なぜアセンブリを書く必要があるのか?
もう一つの注目すべき最適化は、コードを小さくするために大部分で16ビットのThumb命令が使用されている点です。命令が小さいこと自体が必ずしも高速化に直結するわけではありませんが、コードが小さければ命令キャッシュの効率が上がります。また、キャッシュラインの使用を抑えるために、T1はIARツールチェーンのコードアライメント機能を活用しています。コードの最後にある NOP 命令がその証拠で、これは後続の関数が8バイト境界に配置されるようにするためのパディングです。プロセッサのキャッシュ構造を詳細に知らなくても、8バイトのアライメントはコードサイズ(パディング量)とパフォーマンスのバランスが非常に良い設定です。
最後に、これほどパフォーマンスにこだわるなら、なぜ最初からアセンブリで書かないのかと疑問に思うかもしれません。それにはいくつかの理由がありますが、主眼はコスト対効果にあります。IAR C/C++コンパイラがポータブルなC言語からこれほど高品質なオブジェクトコードを生成できるのであれば、メンテナンス性の低い非ポータブルなアセンブリコードを記述・維持するコストを正当化することはできません。
次なるステップ
GLIWA T1とIARが、あなたの次期自動車プロジェクトをどのように強化できるか、ぜひご確認ください。GLIWAのタイミング解析ツールや、IARによる車載組み込み開発支援の詳細をご覧いただき、IARの機能安全ソリューションのインタラクティブデモをお試しください。
※このブログ記事のタイトルは、Jakob Engblom氏の有名な論文『Getting the Least Out of Your C Compiler(Cコンパイラの力を最小限に抑える方法)』へのオマージュです。
